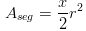In other word, a set of equations that will tell you, for example, how much tinsel, or how many baubles are 'required' for the 'perfect' Christmas tree.
Here is the press release, with the actual formulas.
Now, I have a few issues with this. For one thing, it's a bit silly. Surely the perfect tree is a matter of personal preference, and in that sense can't be defined by a set of mathematical rules.
Plus, it seems kind of arrogant to declare that their way is the 'perfect' way, and that (implicitly) any other way is wrong.
Also, the fact that the equations are preposterously simple (perfect thing = constant*tree height) makes me suspicious of them. But, worse than that, it really bothers me that I have no idea how they were derived.
But I'm starting to rant.
The equations in question were actually from a 'study' by the Sheffield University Maths Society (student from my university), and were commissioned by Debenhams (department store). So, I dunno, maybe I'm just bitter that no-one's ever commissioned me to do maths.
Anyway. If they'd said that these were equations for an 'ideal' Christmas tree, then I'd consider that more reasonable. You can say, for example, that the ideal Christmas tree should strike a balance between too many and too few decorations, etc.
So, to that end, I'm going to have a crack at deriving some, more general, 'Equations for an Ideal Christmas Tree' of my own.
Lights
Before we start, there's one simplification we need to make - we will assume that Christmas trees can be approximated to a smooth, regular, right-circular cone - height h, and base radius r.
There's going to be a certain degree of error as a result of this approximation, but I'm not going for perfect.
Okay. So, for lights, there's actually a justifiable basis for an ideal - the ideal tree should have its lights evenly distributed.
Or, to put it another way, you ideally want to wrap your lights such that you have a (roughly) constant light surface density (lights per unit surface area); because you don't want your tree to be covered in clumps and bald spots.
This seems like a vague point; how do you decide on the correct 'density'?
Well, we actually have two constraints to work from: firstly, we have to wrap a single line around our conical shape, and second, the distance (s) between each pair of adjacent lights on a string will be fixed.
From this, we can layout a (hypothetical) grid on the surface of the tree, so that all the lights are equally spaced out.
So, how do we do that?
1) Draw yourself a cone (tree)
2) Draw a grid
3) Draw lights at the points where the grid lines meet
4) Draw in the proper row lines - these represent the actual string of lights

And if you like, you can play with the distances between rows, and the angles, to get some slightly different layouts


There's a nice short-cut to working this out, without having to worry about lengths of spirals on conic surfaces. To do this, we take advantage of the regular grid layout to work out the lights density (lights per unit area).
Each section of grid is roughly a diamond, with all sides about the same length


We then multiply this density by the total conic surface area (excluding the base) to get the total number of lights needed


So, then, for the triangular grid (theta=60), you get

The only problem then is getting the lights to line up on a grid on the actual tree. So... good luck with that.
Realistically, all of this is mostly irrelevant anyway - you can't go out and ask for, say, exactly 5.83m of lights; you buy your lights in pre-cut lengths. Can't get hold of the 'perfect' length of light? Then your tree is imperfect, and you should feel bad.
Anyway. The point is, if you can get your lights more or less even - so that there aren't any clumps or bald spots -, then as far as I'm concerned, you're on to a winner.
Tinsel
What's interesting about their equation for tinsel is this factor of 13/8. Now, again, I don't know how these equations were derived, so I don't know if this was intentional; But, 8 and 13 are consecutive Fibonacci numbers. Why is this important? Well, the Fibonacci sequence is closely related to spirals.
In particular, there's this thing you see in nature; for example, if you look at the spirals on a pineapple, the spirals going in one direction might be 13 and the number in the opposite direction might be 8. Or the numbers might be 21 left and 13 right... The point is, the numbers of spirals on a pineapple are always consecutive Fibonacci numbers (or sometimes Lucas numbers).
And you get the same effect on other things, like the spirals of seeds in the head of a sunflower, or the seeds on a strawberry, or the spirals on a pinecone, or a cauliflower, or all sorts of things. Hell, maybe the branches on a Christmas tree form Fibonacci spirals.
Vi Hart explains it better than me.
So maybe that has something to do with that pre-factor. Or maybe not. It's an interesting tidbit, though.
Anyway.
The thing with tinsel is different people like to do tinsel differently - some like to elegantly drape it across the outer branches, others like to wrap up their tree light they're restraining a hostage. It's a matter of preference. But it's going to affect the amount of tinsel you'll need.
Where tinsel differs from lights is, you're not trying to set up a grid, or get an even surface density. Rather, in this case, you'd probably want to wrap it such that the rows are more horizontal, with a roughly constant vertical separation.


Extras
The star/angel is going to be some fraction of the height of the tree.

Baubles, I haven't a clue how they came up with those numbers. The factor of sqrt(17) makes me think some geometry was probably involved, but I dunno.
You would probably want to figure it out as some ideal ornament surface density, Db (like with the lights). In this case, the number of baubles needed would be something like

Thoughts
Here are various things Ben Goldacre, of Bad Science, has said on the subject of commissioned, 'perfect' formulas. Here is an article by mathematician, Simon Singh. Here is an article on BBC News. And here is a collection of such formulas on Apathy Sketchpad.
To be honest, I wouldn't bother with any of this; their equations, or mine. I mean, would you really want a tree that was 'perfectly' decorated? Cold and artificial are the words that come to mind.
And, frankly, I'm not sure my equations would actually work in practice.
I'd say, use your best judgement on how much of everything you'll need, and just do your own thing. Have fun with it!

Our Christmas tree is imperfect. In fact, it's gloriously imperfect. No, seriously, it's a mess.
My ex's family used to construct these massive, elaborate, works-of-art trees; with yearly colour schemes, and matching baubles, and everything. By comparison, she described our tree as kitsch.
But it's adorned with all the baubles, and tinsel, and decorations we accumulated over the last 20-odd years; at least, the ones that haven't been lost or broken. And, in a sentimental sort of way, it is perfect.
Well, okay, not perfect. But, damn it, it's ours.
Oatzy.
[I want you to know, I had no part in decorating that tree.]
[...And, yes, that's a weeping angel on top.]